
Black Box Testing
.webp)
There are many ways to discover and design tests in software engineering. One categorization of testing techniques is black box testing versus white box testing. In black box testing, we test a system without concerning ourselves with the technical implementation. We use it in many stages of the software development lifecycle. It's useful because it looks at the system from the user's perspective.
What Is Black Box Testing?
As mentioned, black box testing is testing that doesn't look at the internal structure of the system under test. It doesn't look at the code of a software product to discover new test cases. It regards the system as a black box, hence its name. A box in which we can't look. The only thing that matters is that, given a certain input, we expect a certain output. And we look at only this output to verify if the test passed. This form of quality assurance checks the external quality of the code.
Black box testing can be done from the lowest level (unit tests) to the highest level (end-to-end tests) of our application. In the case of a unit test, the test calls a function with certain inputs and verifies the output. If you want to write a black box unit test, the unit can't have any dependencies. If it does have dependencies, you'd have to mock or stub them. That would make it a white box test, because the test now "knows" about the implementation of the unit. Another option would be to make it a black box integration test, i.e. using the real implementation without the test knowing this.
We can also design our test scenarios at the highest level of our application. In essence, this means using the full-fledged application in functional end-to-end or UI tests. The tester is not concerned with how the feature is implemented, only with the outcome of the feature. To design black box test cases, the tester needs knowledge of the application's features, the requirements and specifications, and the end user who will be using the software.
As we can see, the above cases have two different roles: A developer who writes unit tests, and a tester who executes end-to-end tests. It shows that black box testing can be performed by anyone with the skills to do so: developers, testers, managers, and end users. We can also see that black box testing occurs at different levels in the development lifecycle: from development to release.
Black Box vs. White Box Testing
How does black box testing compare to white box testing? In black box testing, we don't make any assumptions about the inner workings of the system we're testing. Whereas in white box testing, we test the internal control flow of the target of our tests. In the case of software, this means the tester can look at the code and design tests based on the possible code paths they see. The test can also verify that certain side effects occurred when executing the test.
By looking at the inner workings of the code, white box tests can discover specific edge cases. But a tester might also miss potential test cases that weren't apparent by looking at the code, but that were part of the requirements. By focusing only on the implementation, we might be "tricked" into thinking this is the correct implementation and design our tests according to the code we see, instead of the specifications that were requested.
What Is Gray Box Testing?
It should be clear now that both methodologies have advantages and disadvantages. That's why a software development team doesn't have to choose one or the other. Most teams use a combination of both. This is called gray box testing. It gives testers all necessary information to come up with the most complete test suite possible.
Types of Black Box Testing
We can apply the black box testing technique to various types of tests. For this article, we'll look at functional and non-functional tests.
Functional Testing
Functional testing is done when we test our system for the functionalities that we implemented. This is usually at a higher level, like user interface testing, end-to-end testing, smoke testing, or user acceptance testing. But we can also test the implemented functionalities of our software during integration testing or unit testing.
When we do so, we can test the system without knowing the inner workings. We can start entirely from the requirements and specifications. We can use these to identify test cases, execute these cases, and verify the results. That's what makes these tests black box tests.
Often, we will repeat these tests long after the features have been implemented and released. The tests are then part of our regression testing, ensuring features keep working as intended and don't break because of new changes.
Non-Functional Testing
In non-functional testing, we test parts of our application that don't really have a functional impact on our users. If the tests fail, the software may still be able to solve the user's problems. But maybe it won't work as well as it could usually work. Examples of non-functional testing are usability testing, load testing, performance testing, scalability testing, security checks, and crash recovery testing.
Non-functional tests are mostly black box tests. These type of tests don't concern themselves with the specific implementation of the software, but rather they check for certain issues that the system as a whole has.
Tools Used in Black Box Testing
We mentioned that black box testing is ideal for higher-level tests like UI testing and end-to-end testing. Of course, we can perform these tests manually by using our application, but that doesn't scale well. So which testing tools can help us more easily create black box tests?
A tool that implements the Gherkin language (like CucumberJS or SpecFlow) makes it easy to write up tests without the need to know a programming language. It forms an abstraction over code that automates the application. Although we can also write white box tests with the Gherkin language, it's ideal for higher-level black box tests.
Another type of tool is a record and playback tool. Tools like Selenium, Appium, and Waldo allow testers to use an application and record the steps they went through. Later, the tool can run through these steps again and perform any verifications the tester specified. There is no need to know anything about how the features were implemented.
Because black box testing can be used at all levels of software testing, we can also design these tests with unit testing libraries.
Pros and Cons of Black Box Testing
We already hinted at it briefly, but let's take a look at some advantages and disadvantages of black box testing.
One advantage is that it makes us think like an end user. What do we want the software to do? Our tests will cover real use cases in ways that mimic how the user will use the product.
In doing so, we can also change the underlying source code more easily. As long as the feature remains implemented correctly, the test should continue to pass. This makes refactoring easier, because the test isn't checking the implementation, only the outcome.
Another advantage is that this way of testing doesn't require (as much) technical knowledge. Especially with end-to-end testing, testers only need to know how to use the product.
A possible disadvantage is that sometimes, we actually want to test the internal implementation. Maybe we want to verify that certain records have been written to the database, even if this has no relevance to the user of our software. Also, looking at the code might help us think of certain edge cases that need to be tested as well. For example, cases that weren't apparent by looking at the requirements.
Black Box Testing Techniques and Examples
Let's look at some specific black box testing techniques.
Equivalence Partitioning
Using equivalence partitioning, we design test cases by creating "partitions" (or equivalence classes) of test cases where all inputs in a certain partition can be regarded as equivalent. Take a function that receives a birthdate as input and verifies that this date makes the user 18 years or older. Basically, this function has two partitions that can be used for its tests. First, a date range that should return false because the user is younger than 18, and a date range the should return true because the user is 18 or older.
Instead of executing hundreds of tests for different inputs, we can basically reduce it to two test cases. Optionally, we could identify a third partition if we regard the cases where someone is exactly 18 years old as a special case.
Equivalence partitioning is a black box testing method because we only look at the specifications to design our tests.
Boundary Value Analysis
Boundary value analysis builds on the equivalence partitioning technique. With this technique, we take input values at the boundaries of our partitions. In the above example, we would take dates that make the user one day younger than 18 years old, exactly 18 years old, and one day older than 18 years old.
Again, no knowledge of the code is required, only knowledge of the functional requirements.
Decision Table Testing
Decision tables are a useful way of visually representing the different inputs and expected outputs of a system. Each line in the table represents a test case. This is useful for more complex test cases with many variables.
Take a look at this table:
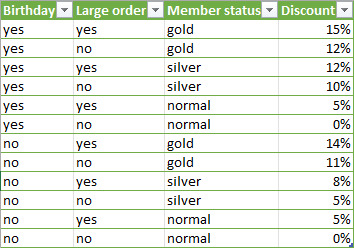
It contains the data for a discount calculation routine. The decision table is much clearer than summing this up in a long specification text. Both developers and testers can use it to implement and test the system. The tester can identify the necessary test cases without looking at the implementation.
State Transition Testing
State transition testing is a technique that's ideal for systems that transfer from one state to another. As an example, think about a system that processes videos. The system is designed in such a way that it can be "idle," "processing," or "paused". When the system receives a video, it'll move from "idle" to "processing." If it receives a file it can't handle, it'll do nothing and remain "idle." And finally, a user should be able to pause and resume the video processing.
We can graphically clarify this with a state diagram:
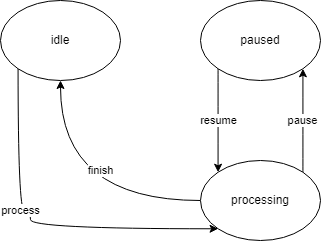
This diagram clearly shows us the different transitions from one state to another, and it can help identify test cases for our tests. The tests that we design based on this diagram won't be complete, of course. We will still want to verify the outcome of the video processing. But the state transition technique gives us a visual representation of the system, making it easier to discover new test cases.
Error Guessing
In this technique, the tester tries to find bugs by "guessing" which conditions or actions may lead to issues with the software application. A good tester has enough experience to know the type of actions and inputs that typically lead to errors in software. Often, these are cases that developers didn't think about. Things like using special characters in inputs, large files for file processing, and double clicking buttons to trigger back-end logic twice.
Black Box Testing in Review
Black box testing is a technique of testing where we test our system without looking at the inner implementation details. It differs from white box testing, where we look at the implementation to identify new test cases. It’s a form of behavioral testing because we verify the external behavior of the system. Most teams use a combination of both, i.e. gray box testing.
To discover new test cases, we can use techniques like equivalence partitioning, boundary value analysis, decision tables, state transition diagrams, and error guessing. These techniques don't require testers to look at the implementation, and as such, don't require technical knowledge.
Black box testing is ideal for both functional and non-functional testing. It can cover all the way from user acceptance testing and UI tests to performance and security testing. We can even apply the black box testing technique to lower level tests like integration and unit tests.
In the case of functional end-to-end tests, we can use tools like Selenium for web applications or Waldo for mobile applications.
This post was written by Peter Morlion. Peter is a passionate programmer that helps people and companies improve the quality of their code, especially in legacy codebases. He firmly believes that industry best practices are invaluable when working towards this goal, and his specialties include TDD, DI, and SOLID principles.